Agentic Engineering: From Architecture Document to Delivery Plan
Architecture documents are often treated as the end of design work. In an effective engineering organization, they are the beginning of delivery work. The architecture document and the developer design decisions usually get converted to concrete executable task backlog for the engineering team. The engineering team lead and the program or product manager work together to perform this conversion.
Recently, I worked on creating a task rewriting a complex industrial software. The source design describes a replacement for a legacy SignalR/ASP.NET edge server with a Go-based middleware service that coordinates field device systems, operator controller apps, and admin dashboards at remote industrial sites. It specifies the architectural style, transport strategy, runtime behavior, safety constraints, persistence rules, observability expectations, security model, test strategy, and rollout approach.
We started with a strong architecture document but it did not tell a team which work must happen first, which work can happen in parallel, which ambiguities must be resolved before sprint planning, or how to turn a safety requirement like “E-Stop p99 < 100 ms” (Emergency stop signal) into stories, acceptance criteria, test gates, and release evidence.
This is where agentic planning became useful for us. Agents can read the architecture document, extract its delivery-relevant facts, challenge gaps, and synthesize a backlog that preserves the architecture’s intent. Our goal was not to have an agent invent a project plan. The goal was to have agents compile, cross-check, and structure the plan from the design.
This article walks through that process using the anonymized Jira delivery plan as the case study.
The Source Material
The architecture document defines an edge-management middleware service with these major characteristics:
- A Go modular monolith using hexagonal architecture, also known as Ports and Adapters.
- A domain core responsible for device group management, field-device finite state machines, ownership rules, E-Stop propagation, and device group’s limit computation.
- ZeroMQ for real-time communication with field devices and controller apps.
- REST APIs for admin dashboard and auth sidecar communication.
- Watermill for cold-path command routing.
- Go channels for the hot sensor and safety path.
- PostgreSQL with an ORM for durable state.
- Authentication and authorization through a sidecar.
- Configuration through a sidecar.
- Hosted error tracking and metrics for operational observability.
- Docker Compose as the per-site deployment target.
It also defines constraints that are not optional:
- E-Stop must reach all field devices within 100 ms at p99.
- Safety and control messages must not be silently dropped.
- Restarts must be safe by default.
- Devices must be offline until reconnection proves otherwise.
- Controller ownership after restart is only a logical association until an operator explicitly reconfirms motion-affecting operations.
- Partial network partition inside a device group causes disband and operator alert.
- The system must support up to 100 field devices, 10 controller apps, and 10 admin dashboards.
- Production rollout starts at Customer A, then Customer B, with rollback to the legacy system.
An agent cannot ignore any of that. A useful plan has to preserve those constraints and turn them into executable work.
The Planning Problem
The hard part is that architecture documents are organized for understanding, while delivery plans are organized for execution.
The architecture has sections like:
- Transport strategy by message criticality.
- Hexagonal architecture design.
- Runtime messaging.
- Hot path versus cold path.
- Graceful startup, restart, and shutdown.
- Network partition and state recovery.
- Data and persistence.
- Observability and SLOs.
- Security architecture.
- Testing strategies.
- Rollout and migration.
A delivery plan needs different questions answered:
- What must be built first so the rest of the team can work?
- Which requirements are safety-critical and need stronger evidence?
- Which architecture decisions imply reusable work tracks?
- Which external dependencies can block progress?
- Where should quality gates live?
- What belongs in sprint stories versus milestones versus release criteria?
- What assumptions must be resolved before implementation starts?
Agentic planning is useful because agents are good at repeatedly transforming structured information across levels of abstraction. In this case, the process turned a 30-page architecture design into a six-milestone delivery plan plus a scoped placeholder for audio/video streaming.
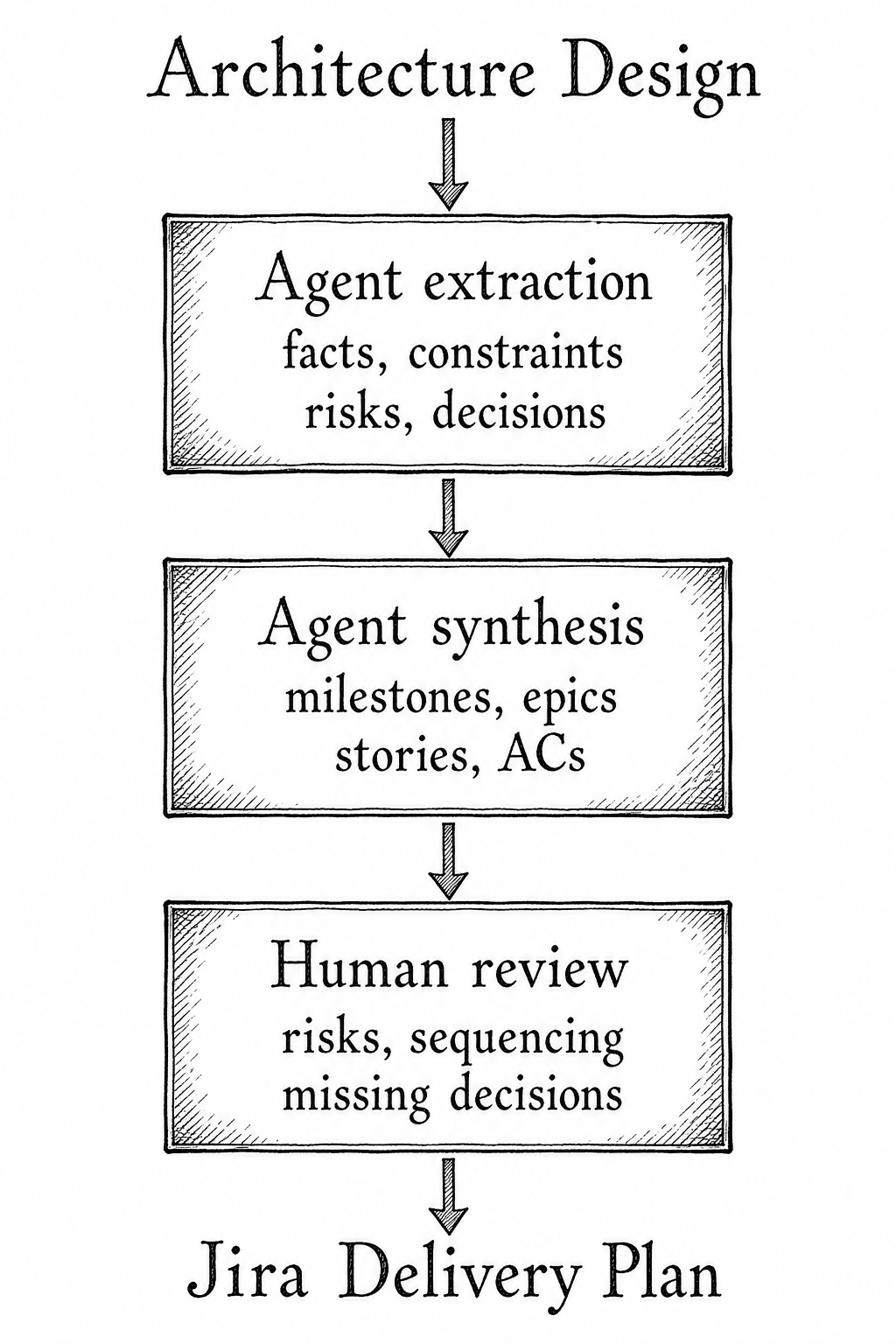
The important point here is the review loop. Agents accelerate the conversion, but the human team members remain responsible for whether the plan is coherent, safe, and aligned with real team constraints.
Step 1: Extract Delivery-Relevant Facts
The first agent task is not to generate stories. It is to extract facts.
For the anonymized service, the extraction pass organized the architecture document into planning inputs:
- Product scope: fleet management, user management, state management, message routing, testing, observability, perception, automation hooks, and audio/video streaming.
- Non-goals: dashboard UI design, controller app architecture, legacy gateway connection, controller app logging pipeline, wireless and physical E-Stop systems handled outside the middleware service, and strict compliance implementation.
- Runtime components: Go service, ZeroMQ transport, Watermill router, PostgreSQL, an ORM, structured logging, hosted observability, and Docker Compose.
- Domain responsibilities: FSM, device group management rules, ownership eligibility, most-restrictive limit computation, E-Stop propagation, idempotency.
- Message classes: safety, control, telemetry, administrative, peripheral.
- State categories: checkpointed, reconstructable, and not persisted.
- SLOs: command success rate, E-Stop latency, availability, dead-letter rate, error budget.
- Testing obligations: unit tests, mutation tests, fuzz tests, integration tests, contract tests, E2E simulation, chaos, performance, soak.
- Rollout obligations: data migration, red-green cutover, rollback, and Customer A / Customer B site acceptance testing.
This fact extraction is where agents prevent a common planning failure: treating all sections of the architecture document as equal. They are not equal. Some sections describe implementation mechanics. Some describe business behavior. Some describe operational proof. Some describe release risk.
For example, “ZeroMQ client” is an implementation fact. “E-Stop must reach all field devices within 100 ms” is a safety constraint. “legacy document layout to ORM entities” is a migration risk. A good plan needs all three, but it should not handle them at the same level.
Step 2: Convert Architecture Boundaries into Work Boundaries
The architecture chose hexagonal boundaries because the middleware service sits between multiple transport protocols and a safety-critical domain. That choice is also a planning gift.
The domain core can be built and tested separately from adapters. The ZeroMQ and REST adapters can be developed against ports. The persistence layer can implement outbound ports without leaking ORM details into domain code. The hot path and warm/cold path can become separate implementation tracks.
The delivery plan used those boundaries directly:
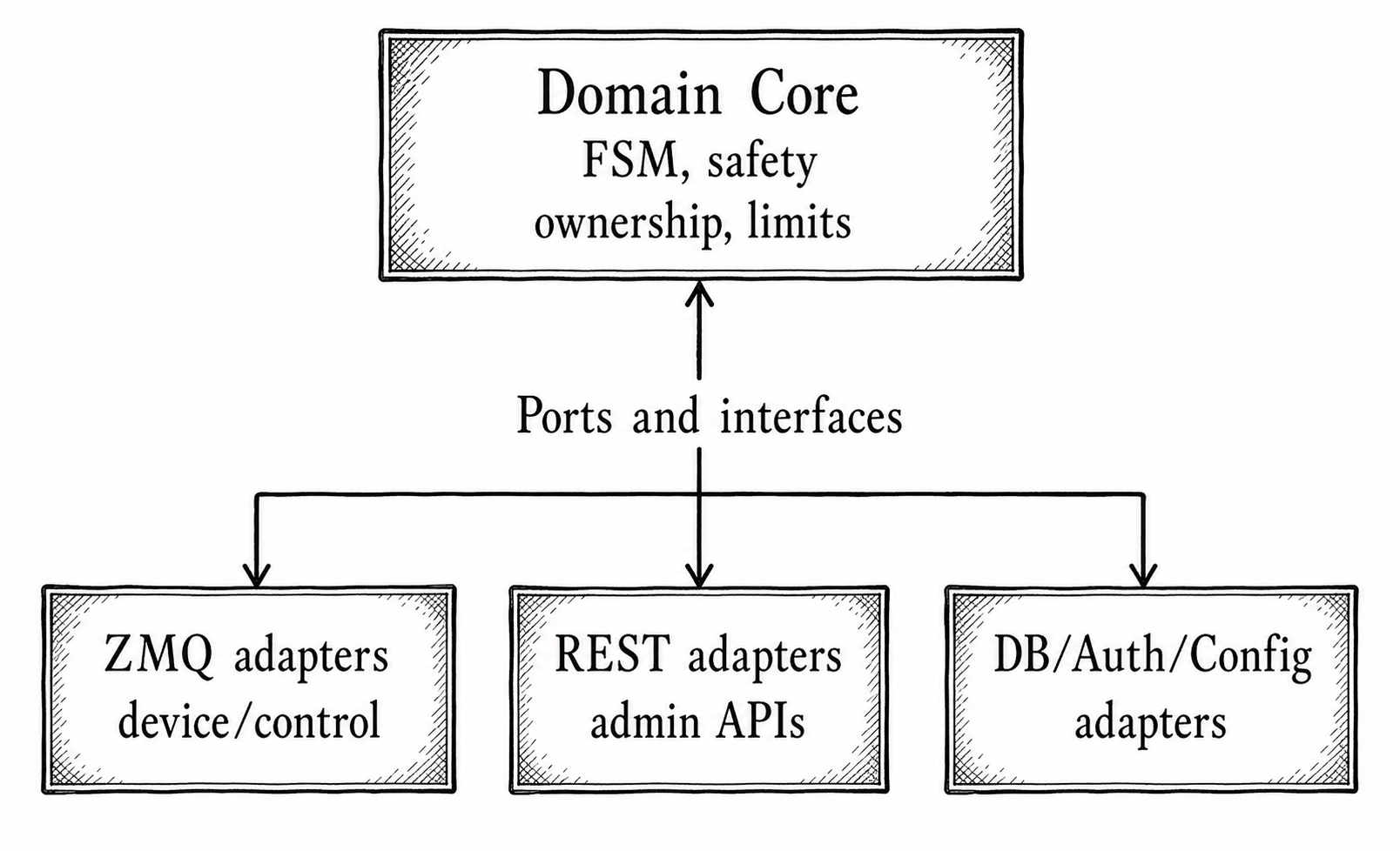
This gave the plan a natural decomposition:
- M1 establishes repository, CI, composition root, local stack, health, logging, and port skeletons.
- M2 builds core domain and messaging MVP.
- M3 adds persistence, authentication, admin APIs, peripheral integration, and configuration.
- M4 completes safety, reliability, recovery, and security behavior.
- M5 proves the system through testing, observability, performance, and chaos.
- M6 handles migration and production cutover.
- M7 holds audio/video streaming as in-scope but underspecified.
That milestone order did not copy the architecture document section-by-section. It translated architecture dependency into delivery dependency.
Step 3: Separate the Hot Path from the Warm/Cold Path
The architecture makes a crucial runtime distinction:
- Hot path:
ZeroMQ -> Go worker -> channel -> batch worker -> domain ports. - Cold path:
ZeroMQ/REST -> Watermill -> command handler -> domain ports.
That distinction affects planning. The hot path exists because sensor and safety traffic need low latency and predictable allocation behavior. The warm/cold path exists because ownership, device configuration, mode switches, admin operations, and peripheral commands benefit from validation, logging, retry, and workflow-style handling.
The plan therefore split messaging work into separate epics:
- ZeroMQ pub/sub adapter.
- Message envelope and protobuf codec.
- Watermill router and bounded class queues.
- Outbound publisher and retry.
- Golden-message fixture validation.
- Go-channel ingest worker.
- Batch processor with fan-out.
- Entity-partitioned sequential processing.
- Hot-path backpressure metrics.
- Safety timing smoke benchmark.
- Cold-path command handlers.
This is a good example of agentic planning preserving design intent. A weaker plan might have created a single “Implement messaging” epic. That would hide the highest-risk part of the architecture inside a broad bucket. The agent-generated plan instead kept the hot and cold paths visible.
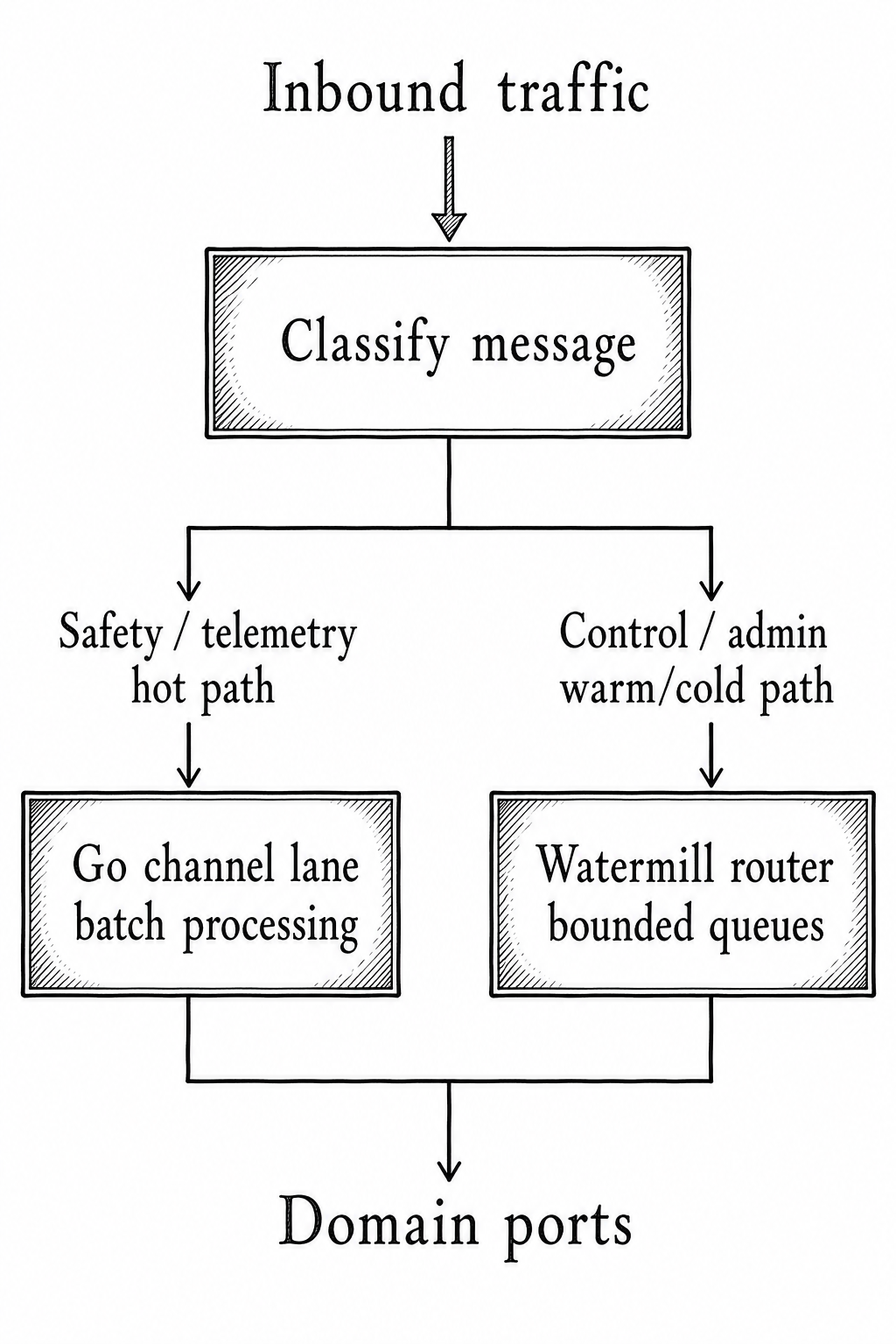
The diagram above is more than technical documentation. It is a delivery planning device. It tells the team which work can proceed independently and where integration risk will appear.
Step 4: Promote Safety Constraints into Delivery Gates
Safety requirements should not sit passively in a requirements section. They need to become acceptance criteria, benchmarks, tests, and milestone exit conditions.
The architecture says:
- E-Stop has a 100 ms end-to-end timing budget.
- Safety messages bypass normal queues.
- If no ACK is received before deadline, the sender transitions to fail-safe behavior.
- E-Stop propagation applies across the devices.
- Restart must recover or surface unconfirmed safety commands.
The delivery plan turns that into M4, “Safety, Reliability & Recovery,” with concrete stories:
- High-priority E-Stop lane.
- All-members ACK aggregator.
- CurveZMQ encryption and device identity.
- Unconfirmed E-Stop integration contract.
- Controller key revocation.
- E-Stop benchmark smoke gate.
- Key/cert lifecycle and replacement.
- Outbox schema and write-before-publish.
- Startup outbox scanner.
- Replay policy for unfinished safety commands.
- Recovery surfacing for unreplayed commands.
It also resolves the timing budget into per-hop gates:
Controller -> Service 30 ms
Service -> device fan-out 40 ms
ACK path back 30 ms
-------------------------------------
Total 100 ms
That budget matters because it changes the shape of the stories. “Implement E-Stop” is not a useful story. “All-members ACK aggregator with a 70 ms site-publish-to-ACK window and operator-visible unconfirmed state” is useful.
Agents are particularly helpful here because they can propagate one safety constraint into multiple artifacts:
- Story acceptance criteria.
- Metrics.
- Benchmark thresholds.
- Chaos test scenarios.
- Dead-letter behavior.
- Restart recovery rules.
- Milestone exit criteria.
The result is that safety becomes an execution structure, not just a paragraph in the design.
Step 5: Build State Matrices Before Writing Stories
The Jira plan contains two authoritative matrices that are more important than they may look:
- Persistence matrix.
- Message-class matrix.
These matrices force the plan to make operational semantics explicit.
The persistence matrix classifies state as:
- Checkpointed: survives restart in PostgreSQL.
- Reconstructable: rebuilt from live transport, heartbeats, telemetry, or recomputation.
- Not persisted: process memory or runtime metrics.
For example, device membership to a group, controller ownership assignments, command-key watermarks, trackfiles, revocation lists, and safety outbox entries are checkpointed. Vehicle connectivity, current sensor values, and derived device group limits are reconstructable. Hot-path queue contents and in-flight worker buffers are not persisted.
That classification drives implementation work:
Runtime state
|
+--> checkpointed ---------> PostgreSQL, migrations, recovery tests
|
+--> reconstructable ------> startup reconciliation, reconnect behavior
|
+--> not persisted --------> metrics, safe loss, no recovery promise
Without that matrix, the team would discover restart semantics piecemeal during implementation. With it, agents can generate persistence stories, recovery tests, and acceptance criteria from a shared source of truth.
The message-class matrix performs the same function for transport behavior. Safety, control, telemetry, administrative, and peripheral messages do not share the same retry, queueing, timeout, deduplication, or dead-letter semantics. The plan makes those differences explicit so stories do not accidentally apply one policy to every message class.
For example:
- Safety bypasses normal queues and uses strict ACK deadlines.
- Control uses bounded wait, at-least-once behavior, command keys, and dead-letter handling.
- Telemetry can drop oldest or coalesce by entity because freshness matters more than replay.
- Administrative work must return explicit errors or retry hints.
- Peripheral commands can be last-write-wins where appropriate.
This is one of the most valuable outputs of the agentic planning process. The agents did not just produce tickets. They produced intermediate planning artifacts that make the tickets safer.
Step 6: Resolve Ambiguity into a Decisions Log
Architecture documents often contain open questions. Some are harmless. Some are project blockers disguised as implementation details.
The source architecture had open questions around partial partition behavior, clock synchronization, E-Stop timing budget, revocation, and MAC-versus-key identity. The delivery plan records those as resolved decisions:
- Protobuf contract source of truth is an internal IPC contract repository on the active v2 development branch.
- Field-device FSM is final and documented.
- E-Stop budget is 30/40/30 ms.
- Partial partition means disband the device group and alert the operator.
- Clock synchronization uses external NTP on all nodes.
- Controller key revocation uses an admin-triggered revocation list.
- MAC is a human label only; the key is the authoritative identity.
- RPO is 24 hours and RTO is 4 hours.
- Deployment target is Docker Compose per customer site.
- Observability hosting uses managed error tracking and metrics platforms.
- TLS certificates come from an internal CA owned by the team.
- SAT completion requires 14-day soak, zero SEV-1, SLO targets met, and customer sign-off.
- Audio/video streaming is in scope for v2 but needs more PRD detail before story breakdown.
This is a critical habit. Agents can draft around ambiguity, but delivery cannot safely proceed if important ambiguity remains hidden. A decision log gives every story a traceable foundation.
Open question
|
v
Clarification with sponsor / tech lead / dependency team
|
v
Decision log row
|
v
Stories, acceptance criteria, tests, release gates
The best agentic plans make assumptions visible. They do not bury them in prose.
Step 7: Turn Test Strategy into Continuous Quality Tracks
The architecture document includes a test pyramid and detailed test categories. A typical project plan might move all of that to the end under a “Testing” milestone. That is too late for this system.
The delivery plan instead creates continuous quality and observability swimlanes from M1 through M5.
Quality starts in M1 with CI, fakes, and reproducible local development. It continues in M2 with domain invariants, fixture validation, and smoke benchmarks. M3 extends integration coverage across persistence, auth, and admin APIs. M4 validates recovery and safety-critical mechanisms. M5 completes the full proof with contract tests, E2E simulation, chaos, fuzzing, mutation testing, performance, and soak.
The CI tiers reinforce that structure:
- PR: lint, vet, unit tests, fast domain tests, small adapter tests, golden-message contract smoke, build verification.
- Merge/main: broader integration suites, migration checks, targeted benchmarks, image publish, staging-oriented verification.
- Nightly: full E2E simulation, fuzz corpus expansion, mutation testing, broader contract verification, scripted chaos.
- Pre-release: 24-hour soak, full performance suite, rollout rehearsals, restore rehearsal, and site-specific pre-cutover validation.
That tiering is important. It prevents the plan from pretending every test should run on every pull request. Agents can help here by matching test cost to trigger frequency.
Fast feedback Deep proof
| |
v v
PR checks -> main checks -> nightly checks -> pre-release gates
The same pattern appears in observability. M1 establishes logs, error tracking, health endpoints, and correlation IDs. Later milestones add queue metrics, hot-path metrics, benchmark output, safety/recovery signals, dashboards, alert routing, and SLO burn-rate surfaces.
Step 8: Model Parallelization Explicitly
A delivery plan is only useful if it accounts for the team that will execute it. This anonymized plan assumes three to four engineers, two-week sprints, and roughly nine months of work.
After M1 lands, the plan maps work to parallel tracks:
- Engineer A: domain core, E-Stop, outbox, restart, dead-letter and recovery.
- Engineer B: ZeroMQ, hot path, cold path, E2E harness.
- Engineer C: persistence, auth, admin APIs, config, migration tooling.
- Engineer D, where available: local stack, observability, contract tests, chaos, performance, dashboards, runbooks.
M1 foundation
|
+--> Domain track --------> Safety / recovery
|
+--> Messaging track -----> Hot path / cold path / E2E
|
+--> Integration track ---> Persistence / auth / admin / migration
|
+--> Quality track -------> Contracts / chaos / SLOs / release proof
The plan also identifies blockers to parallelization:
- FSM definition must finish before meaningful command handler wiring.
- Auth sidecar wiring blocks authenticated admin APIs.
- E-Stop priority lane touches both domain and messaging code, so domain and messaging engineers should pair.
This is the kind of information agents can infer from dependencies, but humans should review carefully. Parallelization is not just about keeping everyone busy. It is about reducing queueing time without creating integration chaos.
Step 9: Keep Release Work in the Plan
The architecture document includes rollout and migration. The delivery plan preserves that as M6 rather than treating it as an operations afterthought.
M6 includes:
- Data migration tooling from the legacy document layout to ORM-backed entities.
- Red-green rollout runbooks.
- Rollback plan to the legacy app/gateway/Edge server setup.
- Customer A activation.
- Customer B activation.
- Site acceptance testing.
- Post-launch retrospective and on-call handoff.
That matters because architecture migration is not done when the code compiles. It is done when production data is migrated, the site is cut over, rollback is rehearsed, support can operate the system, and customer acceptance criteria are met.
The plan’s SAT (site acceptance testing) criteria are concrete: 14-day soak, zero SEV-1, SLO targets met, and customer sign-off. Those criteria prevent “done” from becoming subjective at the end of the program.
What Agents Did Well
The strongest parts of the plan are the places where agents used the architecture document as a constraint system.
They mapped architecture sections into delivery tracks. Hexagonal architecture became foundation, domain, adapter, and integration work. Hot and cold paths became separate messaging epics. Safety constraints became timing gates, outbox work, and recovery stories. Testing strategy became CI tiers and a continuous quality swimlane. Rollout notes became migration and cutover milestones.
They also created useful intermediate artifacts:
- Persistence matrix.
- Message-class matrix.
- Availability SLI definition.
- Cross-milestone dependency map.
- Decisions log.
- Story artifact policy.
- CI tiers.
Those artifacts make the plan auditable. A reviewer can trace a story back to a design section, a decision, or a risk.
Where Our Human Team Members Still Matters
Agents can structure the plan, but they cannot own the consequences.
Humans still need to validate:
- Whether the 30/40/30 ms E-Stop budget is realistic on actual site networks.
- Whether simulated field-device behavior is representative enough before SAT.
- Whether the field-device contract will stabilize in time.
- Whether Docker Compose per site is operationally sufficient for 99.99 percent availability.
- Whether the team has enough Go, ZeroMQ, Watermill, auth, observability, and field deployment experience.
- Whether audio/video streaming can remain a placeholder without undermining the release.
- Whether the plan’s sequencing fits staffing, procurement, and customer-site constraints.
Agentic planning reduces planning labor. It does not remove technical accountability.
A Repeatable Agentic Planning Pattern
The agent-created plan accurately captures that the service is not simply a rewrite from C#/SignalR to Go/ZeroMQ. It is a safety-sensitive architecture migration with strict latency, restart, identity, idempotency, observability, and rollout requirements. It also makes clear where the team can parallelize and where it must serialize work. That is what good agentic project planning should produce. Not a bigger backlog. A clearer one. The following figure shows the steps that led to the final executable plan.
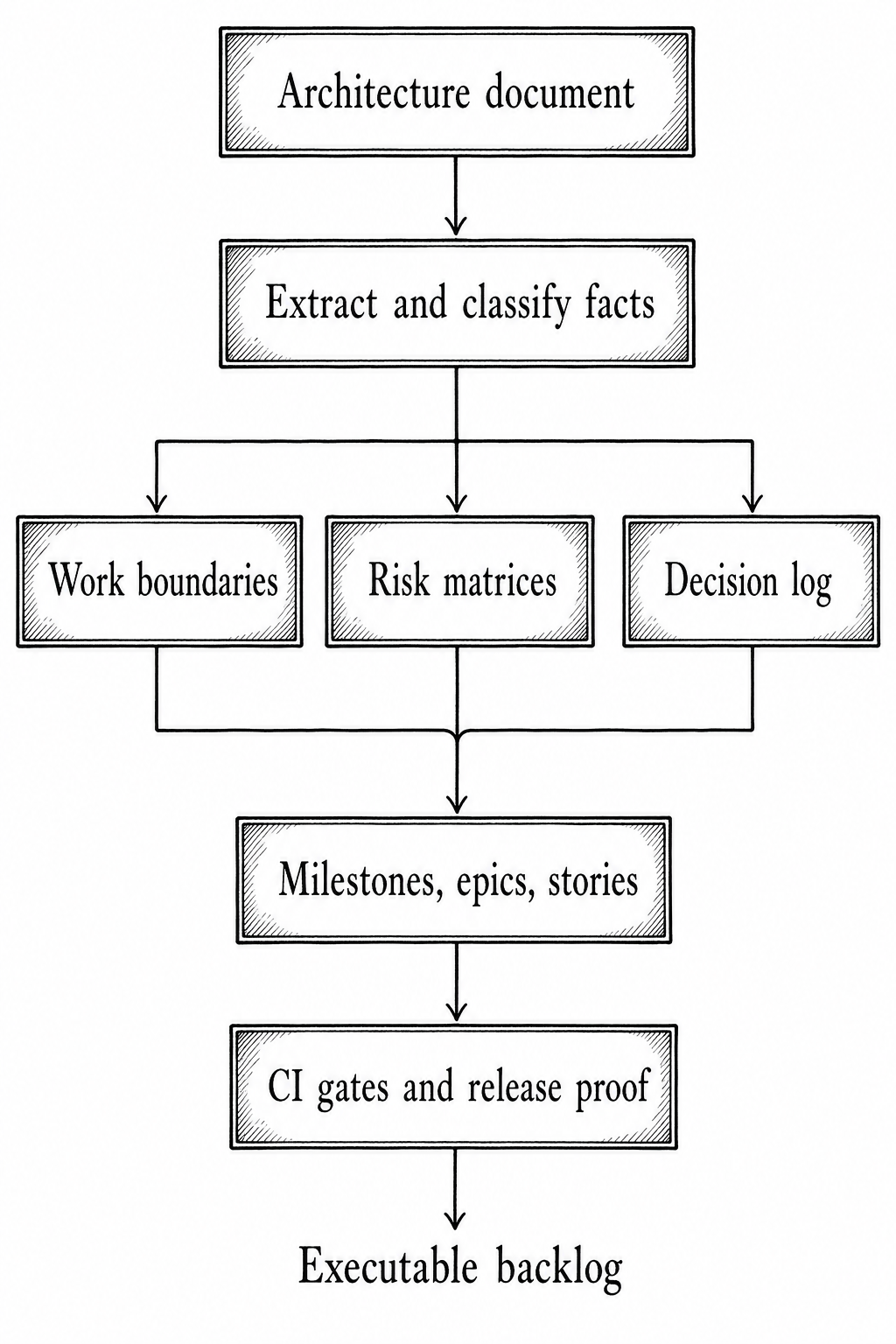
Agents are most valuable when they help teams preserve architectural intent all the way down to executable work. In this case, the architecture document defined the system. The planning agents turned that definition into delivery structure: milestones, risk controls, quality gates, and release evidence.
That is the difference between an architecture document that is admired and an architecture document that ships.