MultiTrust: Subjective Logic as a Runtime for Multi-Agent Trust
In multiagent systems, trust of an agent is a valuable asset since it gives them an ability to reason about their future collaboration, coordination, and plan. Most “trust score” implementations in agentic systems are a single float between 0 and 1. That number is doing two jobs at once — representing how much positive evidence an agent has accumulated, and representing how confident the system is in that judgment — and it collapses them into a value that makes the two indistinguishable. A brand-new agent with no history and a seasoned agent that has run 10,000 tasks with an even win/loss record both land at 0.5. The scalar has no room to say “I don’t know yet.”
MultiTrust fixes this by reaching for the right math. It represents trust as a Subjective Logic opinion — a triple of (belief, disbelief, uncertainty) that sums to one — and exposes the whole machinery as an MCP server, so any Model Context Protocol-aware agent can consult it as a standard tool call.
What Subjective Logic buys you
Subjective Logic, developed by Audun Jøsang in the early 2000s, is a probabilistic logic designed precisely for reasoning under uncertainty where the uncertainty itself must be represented. An opinion looks like this:
opinion = Opinion(
belief = 0.60, # evidence supports trusting the agent
disbelief = 0.12, # evidence against
uncertainty = 0.28, # we don't have enough data to be sure
base_rate = 0.50, # prior: how trustworthy is a "typical" agent?
)
# belief + disbelief + uncertainty == 1.0 (invariant)
The projected trust score — what you use to make a gating decision — is
belief + uncertainty × base_rate. This is the clever bit. A vacuous
opinion (0, 0, 1) projects to base_rate: in the absence of evidence, you
fall back to the population prior. As evidence accumulates, uncertainty
shrinks, and the projection converges on the true belief/disbelief ratio. You
get cold-start behavior and seasoned-agent behavior from the same formula,
with no special-casing.
Under the hood, evidence maps to opinions through the Beta distribution:
belief = positive / (positive + negative + W)
disbelief = negative / (positive + negative + W)
uncertainty = W / (positive + negative + W)
where W is a prior weight (typically 2). Every call to submit_evidence()
is an update to the positive/negative counters; the opinion recomputes
deterministically. There are no magic numbers, no tuned decay constants that
drift out of sync with reality.
That sounds abstract until you compare cold start against real history. With
base_rate = 0.5 and W = 2, the mapping makes the distinction explicit:
| Agent state | Evidence (positive, negative) |
Opinion (b, d, u) |
Projected trust |
|---|---|---|---|
| Brand-new agent | (0, 0) |
(0.00, 0.00, 1.00) |
0.50 |
| Early promising run | (3, 0) |
(0.60, 0.00, 0.40) |
0.80 |
| Mixed but well-observed | (50, 50) |
(0.49, 0.49, 0.02) |
0.50 |
The important case is the first versus the third row. Both might project to
roughly 0.5, but they mean opposite things. The brand-new agent is at 0.5
because the system has no evidence and is falling back to the prior. The
seasoned but inconsistent agent is at 0.5 because the system has a lot of
evidence and that evidence is genuinely split. A scalar score hides that
difference; the opinion keeps it visible.
Architecture
MultiTrust is organized around a single async orchestrator, TrustManager,
with pluggable backends for storage, evidence accumulation, and exposure. The
MCP server is one of several entry points — you can also use the library
directly, gate async functions with decorators, or export/import snapshots
between environments.
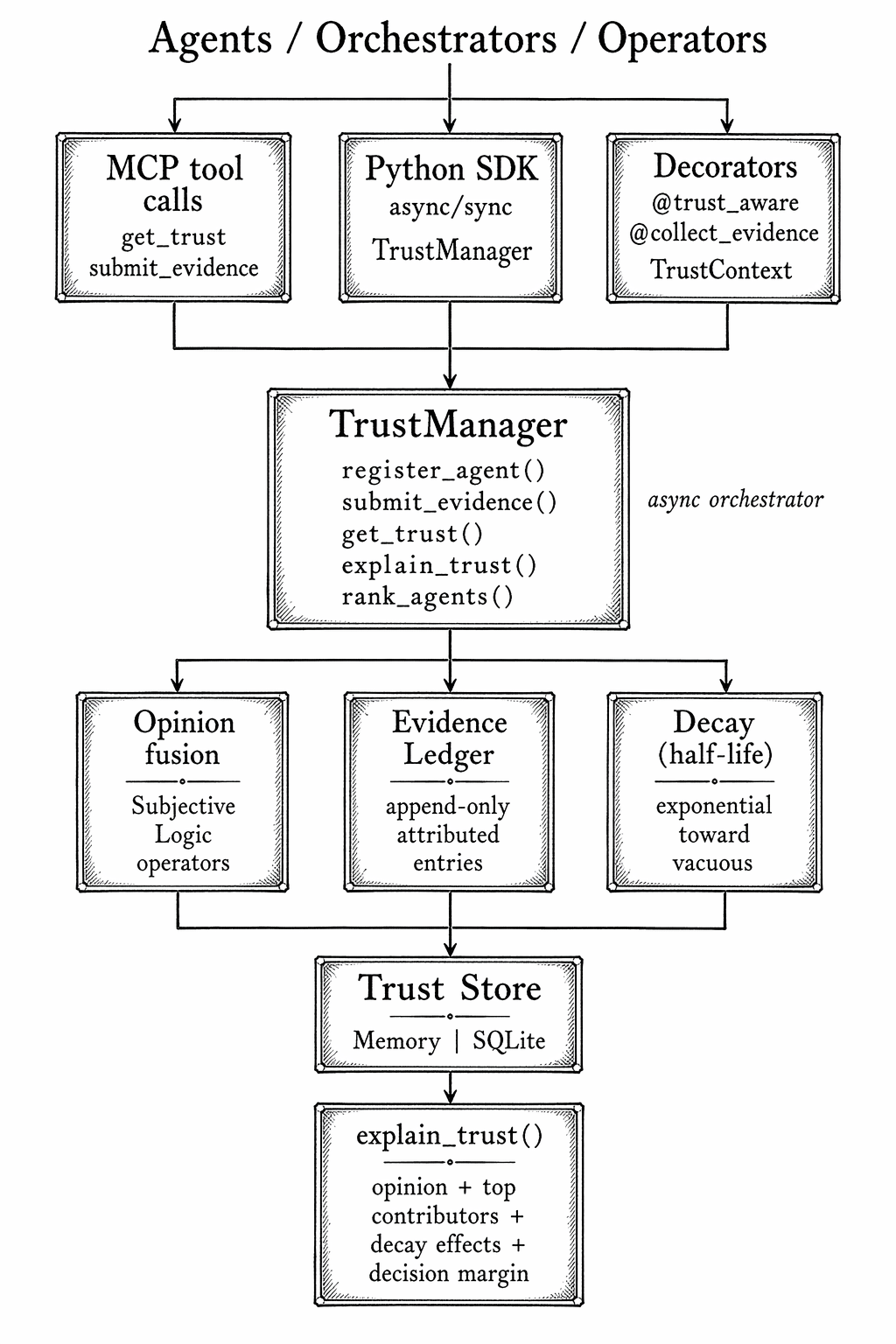
The flow is deliberately one-directional:
- Callers submit observations as
Evidencerecords (agent, authority, positive count, negative count, an optional rule name). - The
TrustManagerfuses those into Subjective Logic opinions using the canonical operators — cumulative fusion for independent authorities, averaging for redundant ones. - Opinions are persisted in the trust store.
- When asked for a trust score, the manager applies time decay (opinions drift toward vacuous at a configurable half-life), projects the current opinion, and returns the scalar.
The EvidenceLedger is the piece that pulls its weight in production. It
stores the individual observations that contributed to an opinion, with
authority IDs and rule names. When something goes wrong and you need to
defend a trust decision — why did we route this request to agent X? —
explain_trust() produces a structured breakdown showing which authorities
and which rules moved the score, by how much, and when.
A representative explanation looks less like a mystery score and more like an audit trail:
agent: fact-checker
current opinion: b=0.31 d=0.46 u=0.23 base_rate=0.50
projected trust: 0.425
top contributors:
- validator / factual_consistency : -0.18 (7 negative observations)
- latency_monitor / timeout_rate : -0.05 (3 degraded responses)
- editor / accepted_corrections : +0.04 (2 successful recoveries)
decision at threshold 0.60: blocked
That is the practical advantage of carrying belief, disbelief, uncertainty, authority, and rule names all the way through the runtime: when the system changes its behavior, you can inspect the reason instead of reverse-engineering it from a number.
A motivating example
The repository ships a
hallucination_firewall.py
demo that captures the intended use case. A research pipeline has a
fact-checker agent whose accuracy silently degrades — perhaps the underlying
model was updated, perhaps a prompt regression slipped in, perhaps the
content it’s checking has drifted out of its training distribution. Each
failed fact-check is submitted as negative evidence against the agent.
Within a dozen or so observations, the opinion shifts enough that
is_trusted(threshold=0.6) returns false, and the orchestrator gates the
fact-checker out of the pipeline before its mistakes reach the final
answer.
The critical thing is that this happens gradually and mathematically, not through a hand-tuned heuristic. The same framework handles the other direction too — agents recover trust as they accumulate positive evidence, and the time-decay mechanism ensures ancient evidence stops dominating current behavior.
If you are building a multi-agent system where different agents have different reliability profiles — and in practice, every non-trivial multi-agent system has this — you eventually need a way to represent and reason about that. Rolling a scalar score is the obvious first move, and it will be wrong in the three places that matter: cold start, recovery after degradation, and explainability. Subjective Logic is a two-decades-old, well-studied framework that gets all three right. MultiTrust is a small, modern, MCP-native implementation of it. The combination of principled math and standard-protocol exposure is, I think, the shape this category of tool should take.
MultiTrust addresses the trust dimension of multi-agent reliability. Two companion pieces cover adjacent failure modes: Tangle detects deadlocks and livelocks when agents form circular waits, and Reverb ensures cached LLM responses don’t go stale when the underlying knowledge changes.