Reverb: A Semantic Cache That Knows When Its Answers Go Stale
Caching LLM responses seems, at first glance, like a simple optimization. Record the prompt, record the answer, serve the answer next time the same prompt comes in. In practice it is a surprisingly deep problem, and the two standard approaches both fail in characteristic ways. Exact-match caches miss on anything short of a byte-identical prompt, which is almost never how users actually ask questions. TTL-based caches serve confidently-stale answers for hours after the underlying knowledge base has changed — the classic hallucination vector dressed up as “we cached it.”
Reverb is a Go library and standalone service that addresses both failure modes. It combines a two-tier cache (exact SHA-256 match, then embedding-cosine similarity) with knowledge-aware invalidation: every cached entry tracks the source documents it was derived from, and a change-data-capture pipeline evicts entries by causality when their sources change. TTLs become a backstop, not the primary correctness mechanism.
Two-tiered approach
The exact-match tier is cheap and essential — a SHA-256 hash of the normalized prompt plus namespace and model ID, looked up in a store. Sub- millisecond latency, perfect precision, zero false positives. It catches retries, duplicated user requests, and programmatic callers that issue the same prompt on a schedule. In production workloads this tier alone typically handles 20–40% of traffic, depending on how much of the workload is human-in- the-loop.
The semantic tier is where it gets interesting. Two users phrasing the same question differently — “how do I reset my password?” vs. “password reset help” — should get the same answer. The tier computes an embedding for the incoming prompt, searches a vector index for top-k nearest neighbors above a configurable cosine-similarity threshold (0.95 by default), and returns the closest hit. Latency climbs to ~50ms, which is still one to two orders of magnitude faster than actually calling the LLM, and recall improves substantially.
The fallthrough contract is the part that makes it work: exact misses do not fail, they degrade to a semantic lookup. Semantic misses do not fail, they degrade to a real LLM call that then writes back through both tiers. Three states — exact hit, semantic hit, miss — all with correct fallback.
Architecture
Reverb is built around clean interfaces for each pluggable component, which is what lets it scale down to an in-memory dev setup and up to Redis plus HNSW plus NATS-driven CDC without code changes. The top-level flow:
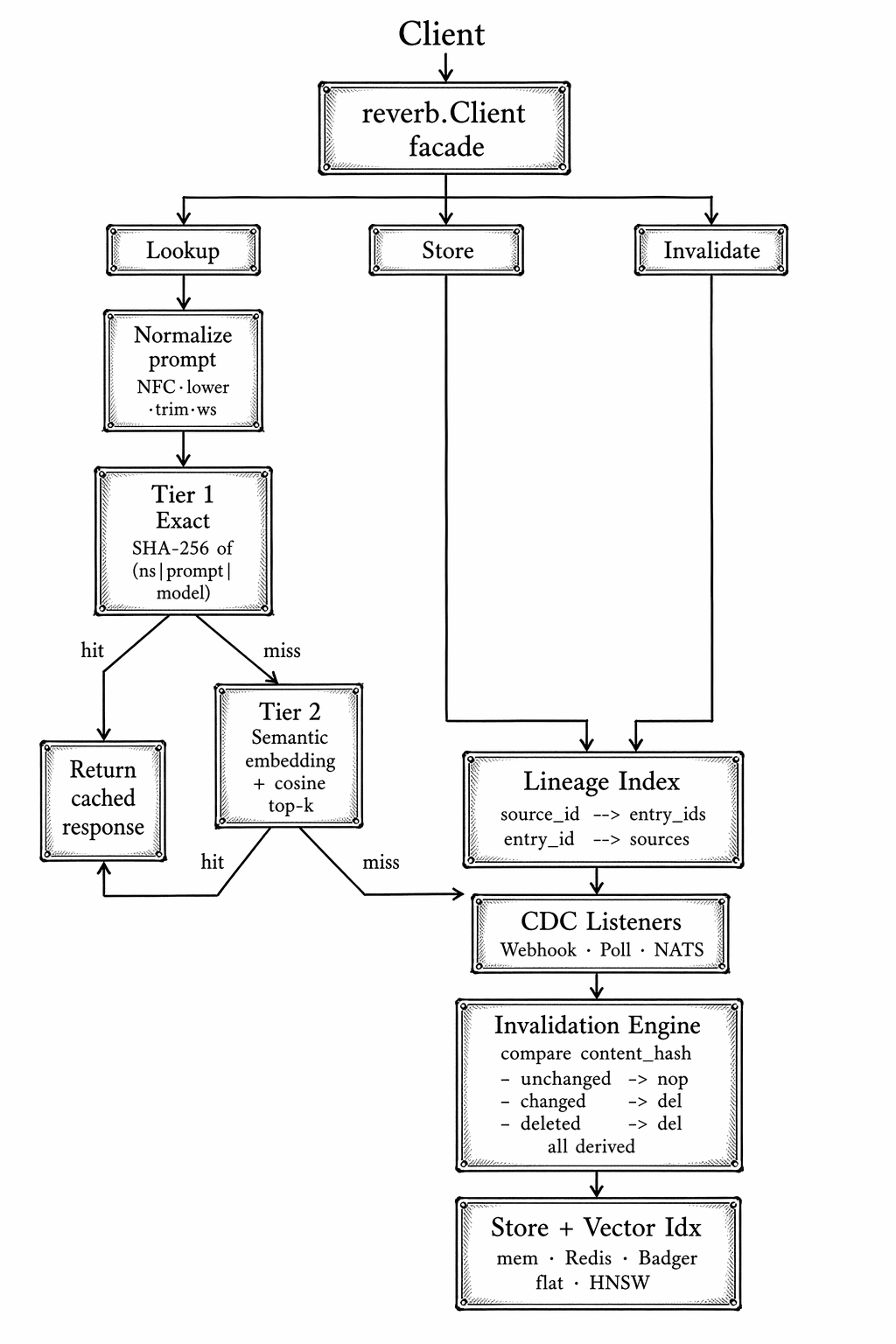
Notice that the invalidation path and the lookup path share no state beyond the store itself.
- CDC events can fire at any time — a webhook from your CMS, a NATS JetStream message, a polling loop against a content API.
- The invalidation engine consults the lineage index to figure out which specific cache entries to evict. Every other cached entry keeps its hit rate.
Two interesting design choices are:
- the two-tier fallthrough, which means the cache has a meaningful answer for most queries, not just byte-identical ones
- the lineage-based invalidation, which means stale-knowledge hallucinations stop being an accepted cost of caching
Neither is a novel technique in isolation — CDN cache tags and hierarchical CPU caches use similar approaches. The novelty is in recognizing that LLM responses are derived data with explicit sources, and that derived-data systems have known-correct invalidation disciplines that work just as well when the derivation is a transformer inference.
Lineage as the first-class concept
When you Store() an entry, you hand Reverb a list of sources — the
documents that contributed to the LLM’s answer. Each source is a (source_id,
content_hash) pair. The lineage index maintains a bidirectional mapping:
source IDs to the set of cache entries they contributed to, and cache entries
to the set of sources they depend on. When a CDC listener reports a change
for source_id = "doc:password-guide", the engine asks the lineage index for
all dependent entries and walks through them:
That is also the contract the application has to honor. Reverb does not infer provenance by itself. Your retrieval layer, tool wrapper, or orchestration code must tell it which source documents actually contributed to the answer. If you omit a source, Reverb cannot invalidate on that source’s change; if you over-attach unrelated sources, you will evict too aggressively. The cache is only as causally correct as the lineage you record at write time.
- If the source has been deleted (zero hash), invalidate every dependent entry.
- If the source still exists but the
content_hashdiffers from the stored value, invalidate. - If the content hash matches (the webhook fired but nothing actually changed), do nothing. Idempotency is free.
Compare this to the naive alternative — TTL-based invalidation, tuned conservatively at, say, 6 hours. During those 6 hours, the cache can serve any number of answers derived from a document that changed 5 minutes after the entry was cached. The user experiences a confident, fluent, completely wrong answer. With lineage-based invalidation, the moment your CMS pushes the webhook, the relevant cache entries are gone.
The operational sequence is short and predictable:
- At
t0, the application stores an answer plussources=[("doc:password-guide", hash_v1)]. - At
t1, the source document changes and the CMS emits a CDC event carryinghash_v2. - At
t2, Reverb looks up every cache entry linked todoc:password-guide. - At
t3, entries whose stored hash is stillhash_v1are evicted from the store and vector index. - At
t4, the next lookup misses the cache and regenerates against fresh knowledge.
This is not a new idea in the abstract — database query caches have done tuple-level invalidation for decades, and CDN cache tag invalidation is a production pattern at scale. The contribution is noticing that LLM response caches have exactly the same dependency structure and applying the same discipline.
The pluggable-backends discipline
Reverb exposes four interfaces, each with two or more implementations:
embedding.Provider— OpenAI, Ollama, or a deterministic fake for tests. The fake (fake.New(n)) is a hash-based embedder that produces stable vectors for stable inputs, which makes integration tests reproducible without requiring an API key. This is the kind of detail that signals the library was written by someone who actually runs tests in CI.vector.Index— a brute-force flat index (O(n)) and an HNSW index (approximately logarithmic search in practice). You start with flat, and when you outgrow it you swap in HNSW with no other code changes.store.Store— memory for dev, Redis for production, BadgerDB for embedded use cases. Theconformancesubpackage ships a shared test suite that every store implementation must pass, which is how the interface stays honest over time.cdc.Listener— webhook, polling, NATS. Each is a different architectural fit: webhook for push-based CMS integrations, polling for systems you cannot modify, NATS for high-volume event streams.
The interface-driven design makes Reverb realistic to adopt: start with all-in-memory (zero infrastructure), move to Redis plus HNSW when you outgrow a single process, swap the CDC listener when your source-of-truth changes. None of those migrations need to touch the application code.
Deployment shapes
Reverb runs as three things, depending on how you want to use it:
- A Go library, linked directly into an application. Fastest path,
lowest latency, no extra process to manage. The
pkg/reverbfacade is the full public API. - A standalone HTTP server (
cmd/reverb). Language-agnostic REST API under/v1/—lookup,store,invalidate,entries/{id},stats,healthz. This is the path if your application is in Python or TypeScript and you want to cache centrally. - A standalone gRPC server, same operations as the HTTP API but with
protobuf-defined contracts in
pkg/server/proto/reverb.proto. Clients in any language can generate their own stubs.
The HTTP and gRPC servers share the same underlying Client, so you can
deploy both protocols side-by-side from the same binary and pick whichever
your calling environment prefers.
Where this fits
I think semantic caching is about to become table stakes for production LLM systems in the same way that ordinary HTTP caching became table stakes for the web in the 2000s. The cost pressure is enormous — every cache hit is an LLM call that did not happen — and the latency improvement is user- perceptible. But “cache LLM responses” is the easy version of the problem. The hard version is “cache LLM responses correctly, even when the world the LLM is reasoning about changes out from under the cache.” That is the problem Reverb is built to solve.
Reverb handles the knowledge freshness dimension of agent reliability. For the trust side — knowing which agents to rely on based on observed behavior — see MultiTrust. For detecting when agents get stuck waiting on each other, see Tangle.