Tangle: Deadlock and Livelock Detection for LangGraph Agents
Multi-agent LLM workflows are, from a concurrency standpoint, small distributed systems. They hold resources, they wait on each other, and — like every other distributed system we have ever built — they can get stuck. The failure mode is worse than an outright crash: no exception is raised, no timer fires, no agent knows anything is wrong. The workflow just stops producing tokens. The operator sees a spinner.
Tangle is a small Python library that catches this class of failure in real time for LangGraph workflows (and, via OpenTelemetry, for anything else). It reuses an idea that has been sitting in operating-systems textbooks since 1972 — the Wait-For Graph — and applies it at the agent layer, where the same topology has quietly reappeared. To be specific, in its current implementation, Tangle provides repeated-pattern detection over message digests.
The failure mode
Consider a four-agent pipeline: researcher → writer → reviewer → editor.
Each agent, under certain states, may wait on output from another. Introduce a
back-edge — say, editor → researcher for a re-research pass — and the
dependency graph now contains a cycle. If every agent in the cycle is
simultaneously in its waiting state, none of them can advance. None of them
will ever advance. The workflow is deadlocked.
Livelock is the subtler sibling: no circular wait, but two agents bounce the same rejected message back and forth forever. A reviewer rejects a draft, the writer revises in a way that changes nothing material, the reviewer rejects the revision. Tokens keep being spent. Progress is zero.
In practice, a deadlock trace looks like this:
researcher waiting for writer
writer waiting for reviewer
reviewer waiting for editor
editor waiting for researcher # closing edge; cycle exists now
At that moment, you do not need a timeout to guess the workflow is stuck. The structure itself is enough: every agent in the cycle is waiting on another agent in the same cycle, so no further progress is possible without external intervention.
Both failures are detectable in principle. The question is how to detect them cheaply enough that instrumentation doesn’t dominate the workflow’s own cost.
Architecture
Tangle separates event ingestion from detection from resolution. The three stages are deliberately independent — you can swap SDK hooks for OTLP spans, switch cycle detection to livelock detection per event type, and chain resolvers in any order. The shape of the system:
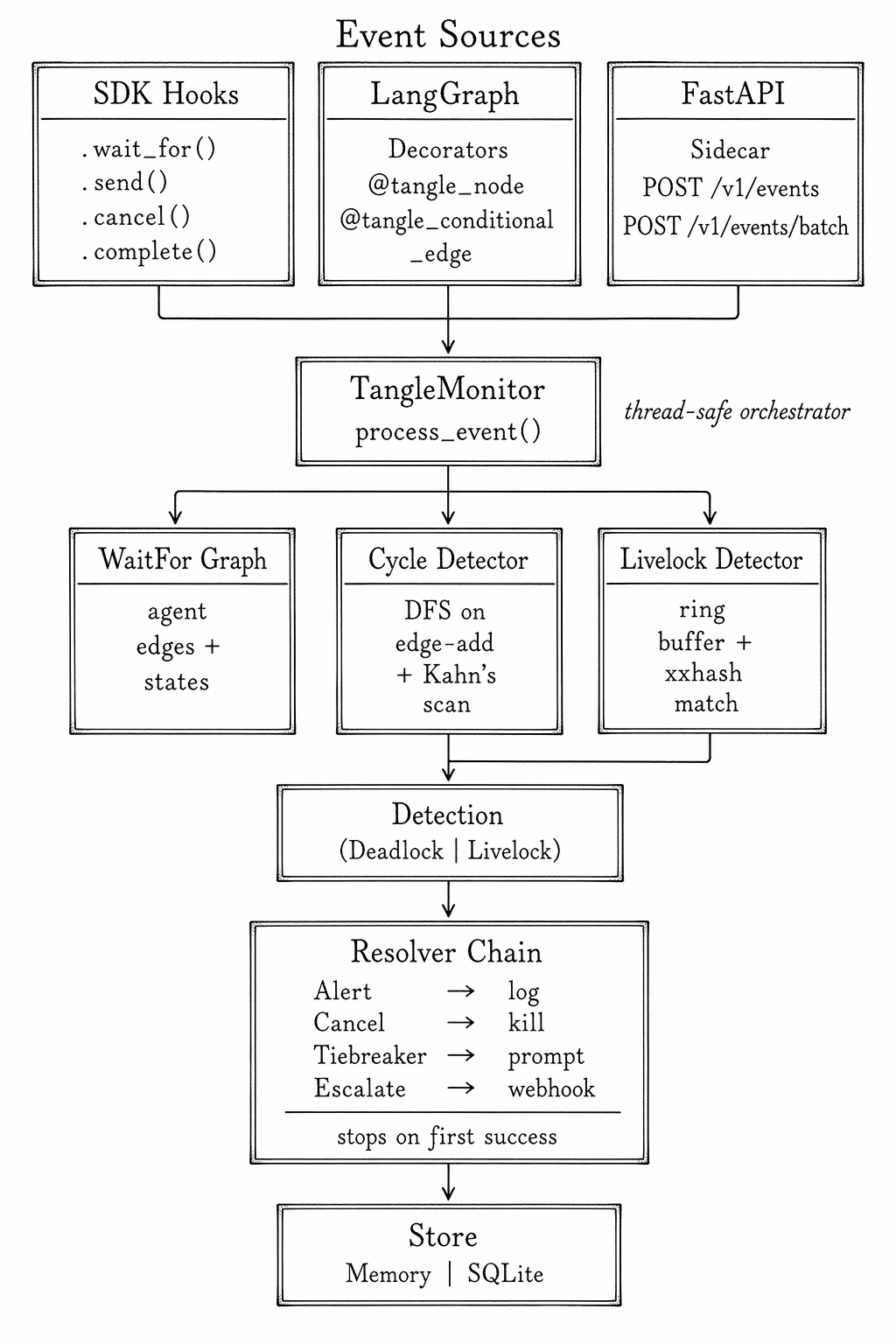
Events flow in from one of three sources. Each event is a small, typed record
(e.g., REGISTER, WAIT_FOR, RELEASE, SEND, CANCEL, COMPLETE). They hit
TangleMonitor.process_event(), which updates the Wait-For Graph and
dispatches to the appropriate detector: WAIT_FOR events touch cycle
detection, SEND events touch livelock pattern matching. When either fires,
the resolver chain runs in order and halts on the first resolver that
succeeds.
Why a Wait-For Graph?
The Wait-For Graph (WFG) is one of those classical constructs that keeps reappearing in disguise. Holt described it in 1972 for kernel deadlock detection. Database engines use it for transaction lock cycles. Distributed lock managers like Chubby and ZooKeeper reason about it implicitly. The insight in Tangle is that an LLM agent holding a conversational turn is, for the purposes of progress analysis, isomorphic to a process holding a resource. Same graph, different vertices.
That matters because cycle detection on a WFG is a well-understood problem with well-understood complexity. Tangle uses two complementary algorithms:
- Incremental DFS on edge-add. When a new
WAIT_FORedge is added, walk back along existing edges from the target to see if you return to the source. O(V+E) worst case, but in practice tiny because multi-agent graphs are shallow. - Periodic Kahn’s-algorithm scan over the whole graph. A topological sort that fails is a cycle that exists. This is the belt-and-suspenders pass that catches anything the incremental detector might race against during concurrent edits.
Livelock is different — no cycle appears in the graph. Instead, Tangle
fingerprints each SEND event’s message payload with
xxhash (chosen for speed over cryptographic strength —
this is a signal, not a security claim) and keeps the last N digests in a
ring buffer. When the same digest reappears more than livelock_min_repeats
times in the window, the detector fires. No semantic understanding of the
message is required; identical repeated content is the signal.
That distinction matters operationally. Deadlock detection here is structural: if a Wait-For Graph contains a cycle, the workflow is blocked in a precise, checkable sense. Livelock detection is heuristic: Tangle is looking for repeated message patterns that strongly suggest non-progress, not proving a theorem about all possible non-progress states. That is still a useful line to draw in production. You can treat deadlocks as mechanically certain and livelocks as high-confidence warnings that deserve intervention.
The LangGraph integration
What makes this practical for day-to-day use is that instrumentation is two decorators:
from tangle import TangleConfig, TangleMonitor
from tangle.integrations.langgraph import (
tangle_node,
tangle_conditional_edge,
)
config = TangleConfig(
resolution="cancel_youngest",
livelock_min_repeats=3,
)
monitor = TangleMonitor(config=config, on_detection=print)
@tangle_node(monitor, agent_id="reviewer")
def reviewer(state):
return {"feedback": review(state["draft"])}
@tangle_conditional_edge(monitor, from_agent="reviewer")
def route_after_review(state):
if state["feedback"] == "approved":
return "__end__"
return "writer" # back-edge — potential loop
The decorators emit REGISTER, SEND, WAIT_FOR, and RELEASE events
transparently. Existing LangGraph code keeps working. Tracking is activated
per-invocation by threading a tangle_workflow_id through the state dict, so
you can roll out detection to a subset of production traffic without changing
the graph definition.
For non-LangGraph workflows (or for multi-language stacks), Tangle can reconstruct the same events from OpenTelemetry spans, which means any tracing instrumentation you already have becomes deadlock-aware for free.
Resolution, not just detection
Detection without a response is an alert that wakes someone up at 3am. Tangle ships several built-in resolvers, for example:
- Alert — the cheap default. Hand a structured
Detectionto a callback, let the application decide. - Cancel youngest — kill the most recently joined agent in the cycle. In practice this is the right default for review/revise loops: it breaks the cycle with minimal loss of context.
- Tiebreaker prompt injection — for livelocks, inject a system message that explicitly names the repeated pattern and asks the agent to change tack. Cheaper than restarting the workflow.
- Escalate — POST the detection to an external webhook for human or upstream-service intervention.
The chain executes in order and stops on the first success. Configure it once; the per-detection behavior emerges from the config, not from scattered try/except blocks in agent code.
Where this fits
If you are running LangGraph in production, especially with conditional edges or multi-agent negotiation patterns, you have almost certainly hit a workflow that hung. The standard mitigation — a coarse wall-clock timeout — is a blunt instrument: it catches deadlocks eventually, but at the cost of cancelling any slow-but-healthy run that exceeds the budget. Tangle’s contribution is to give the same workflow a structural reason to cancel (a cycle in the WFG, a repeated digest pattern) rather than a temporal one (we waited too long). That distinction matters at scale, because it decouples correctness from tail latency.
The approach generalizes past LangGraph. Any system where autonomous components exchange messages and occasionally wait on each other — agent frameworks, workflow orchestrators, multi-model ensembles — has the same failure modes. Tangle is an early, careful implementation of what I suspect will become a valuable tool in building reliable and fault tolerant agentic infrastructure: progress monitors that treat liveness as a first-class property, not a property you check by inference after everything has already gone quiet.
Tangle covers the liveness dimension of multi-agent reliability — detecting when workflows stop making progress. For the trust layer — modeling which agents are reliable based on accumulated evidence — see MultiTrust. For ensuring cached responses stay fresh when source knowledge changes, see Reverb.