Agentic Engineering: Taming a Legacy Codebase
Why This Article Exists
Every engineering team eventually inherits a codebase that has outgrown its original design. Features were shipped, deadlines were met, and somewhere along the way the foundations quietly cracked. Hardcoded secrets found their way into source control. async void started creeping into timer callbacks. Collections got shared across threads without locks. A comment saying // TODO: fix this properly quietly turned into a permanent resident.
This article documents how our team used Claude to audit and harden three legacy services over a multi-month effort. The services were modest in size — roughly fifteen to sixty source files each — but they sat on the critical path of a real-time control system. A crash in any of them meant downtime for physical equipment in the field. That made the usual “just rewrite it” advice completely unacceptable.
What follows is a practical playbook. We walk through how we used Claude for five distinct jobs:
- Refactoring sprawling services back into something understandable.
- Fixing bugs and logging gaps that hid failures from operators.
- Eliminating race conditions in collection access, timers, and state flags.
- Improving code quality across naming, dead code, and error handling.
- Reducing technical debt measurably, without freezing feature work.
High-risk changes were verified with tests first or alongside the fix, especially around concurrency, startup behavior, and logging. Every code sample below has been obfuscated — names, domains, and specifics have been changed — but the patterns, shapes, and lessons are exactly what we encountered in production.
The Landscape We Inherited
Three services sat at the heart of the system. A device-side proxy ran on embedded Linux hardware and bridged a local message bus to a central coordinator over SignalR. A server-side coordinator aggregated state from hundreds of connected devices and fanned out commands to operator consoles. A mobile controller gave field operators a touchscreen interface to issue commands.
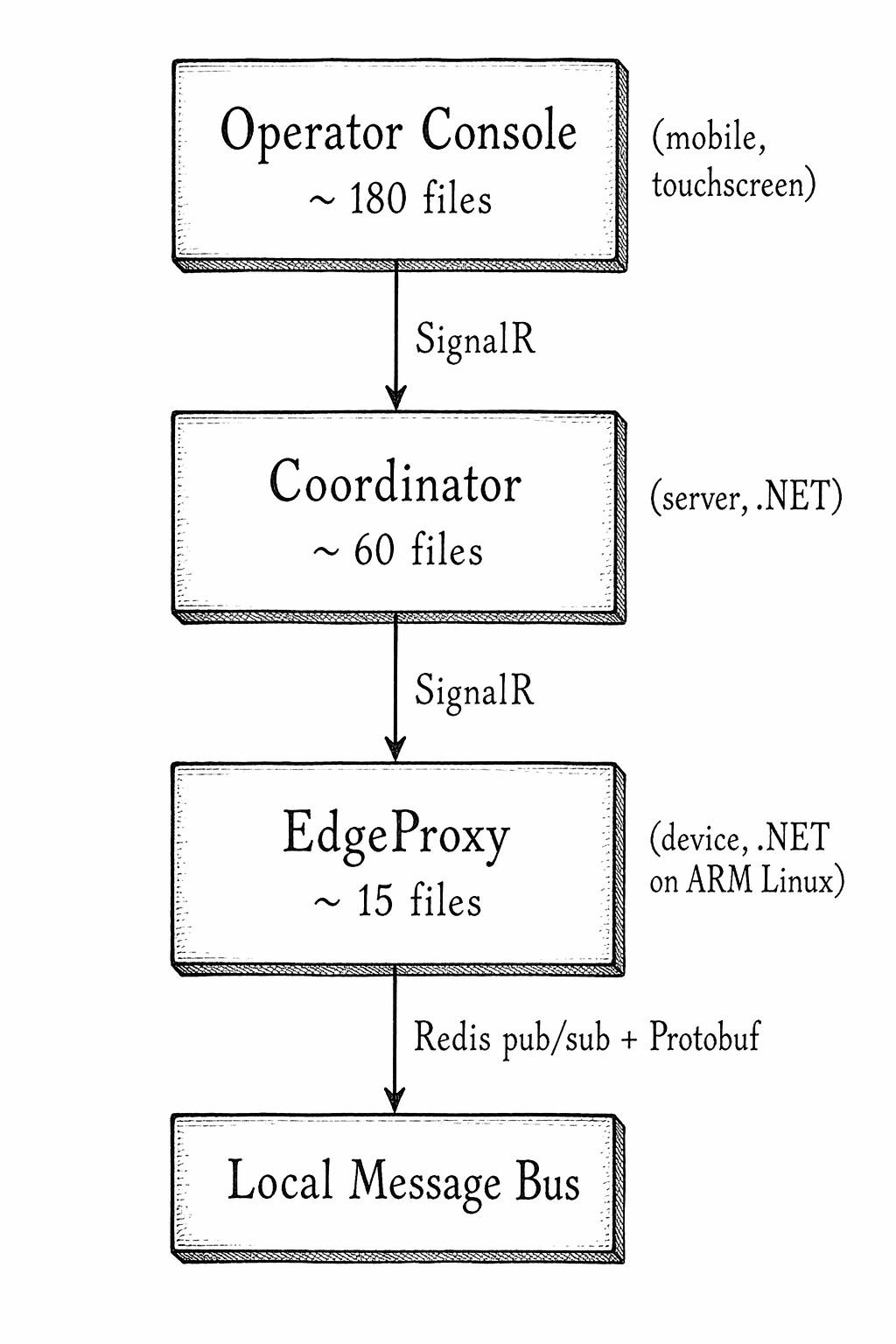
Across the audit documents we generated for these services, Claude surfaced well over 140 issue instances across five categories:
| Category | Issues Found |
|---|---|
| Bugs and logic errors | 32 |
| Race conditions and thread safety | 44 |
| Security and secret management | 9 |
| Logging and observability gaps | 38 |
| Code quality and tech debt | 24 |
Those counts came from multiple audits run on different services and at different points in time, so they are best read as a backlog inventory rather than a mathematically exact “open issue count” at one instant. That distinction matters. Engineers can smell inflated metrics immediately.
What the numbers did tell us, reliably, was where the risk clustered: concurrency, observability, and unsafe async usage. No single human could hold that entire list in working memory while also writing code. That is exactly the kind of problem where Claude earns its keep.
What Claude Did, and What Human Developers Still Owned
Claude was most useful in four places:
- Inventory. Scanning a module and producing a structured issue list with file paths, line numbers, and candidate fixes.
- Pattern matching. Finding every variation of the same bug class:
SafeFireAndForget()without an error callback, mutable dictionaries shared across threads,Task.Delaycalls with unclear units, timer callbacks implemented asasync void. - Drafting small fixes. Once we had a failing test or a clearly defined target, Claude was effective at drafting the minimal change.
- Summarizing conventions. It was surprisingly good at inferring the codebase’s implicit design rules from the parts that were already clean.
Humans still owned the parts that actually determine whether a system stays safe:
- Severity. Claude could identify a race; engineers still had to decide whether it was a theoretical code smell, a real production risk, or already serialized by some upstream mechanism.
- Merge readiness. Many source audits included issues that were fixed on a branch, partially fixed, or still open. Humans had to reconcile audit output with reality.
- Test strategy. Claude could suggest a fix, but engineers still had to decide whether the defect needed a unit test, a stress harness, an integration test, or simply a code review plus a reproducer.
- Stopping. We did not pursue zero issues at any cost. Some low-severity findings were documented and left alone because the churn was not worth it.
Our Working Loop
Every change followed the same four-phase cycle. The loop became muscle memory within the first two weeks.
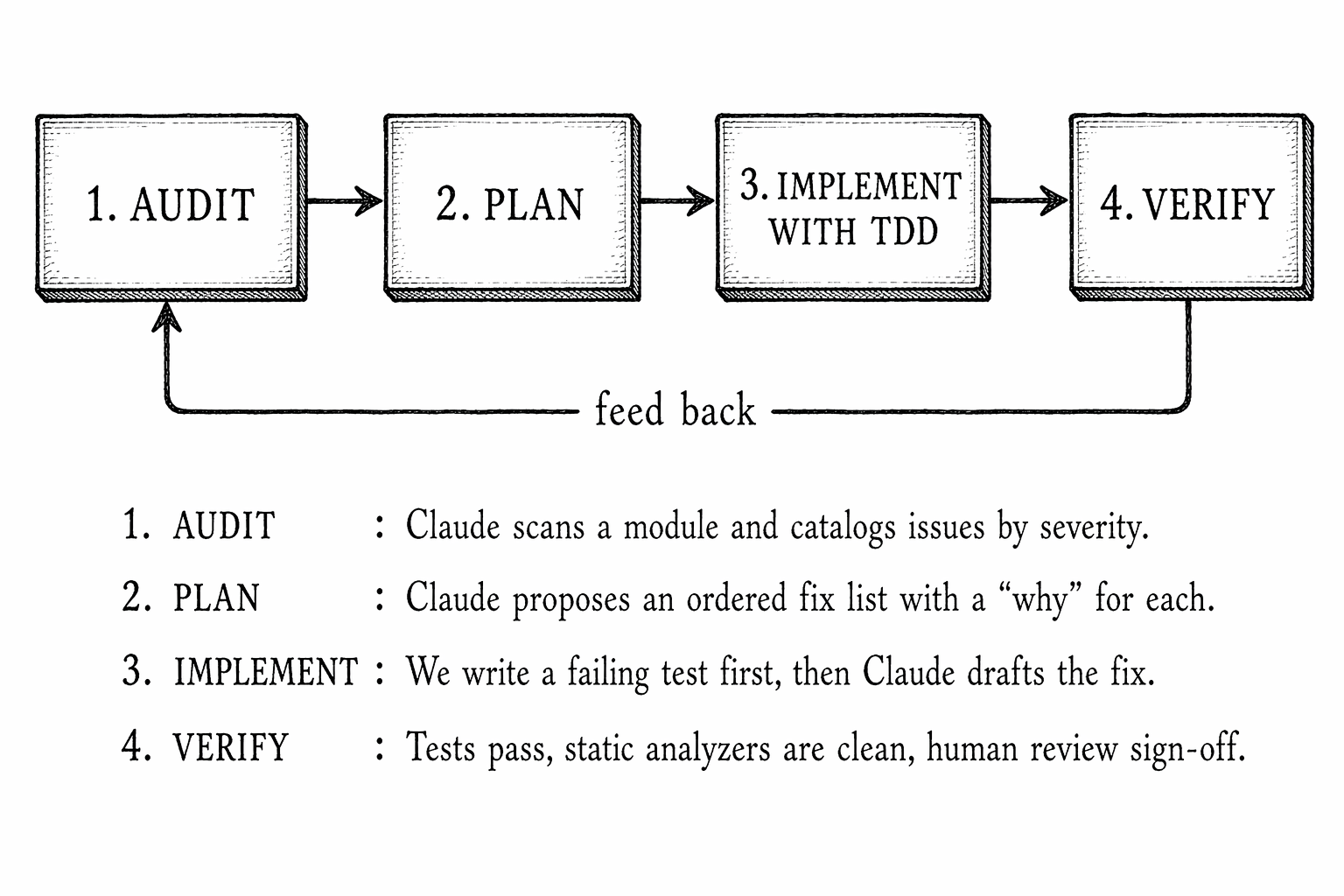
The key insight was that Claude is excellent at the first two phases — the ones humans find tedious — and genuinely helpful at the third phase when guided by an explicit failing test. The fourth phase still belongs to humans, but it becomes fast when the diff is small and the test captures the intent.
Throughout the effort, we produced markdown audit documents. Each one listed every issue, its severity, its file and line numbers, a short explanation of the danger, and a proposed fix. These documents became the working backlog for each service and were regenerated regularly as the code changed.
Part 1 — Refactoring
We asked Claude for a refactoring proposal. The useful part was not “AI architecture.” It was the dependency map: which methods touched transport, which ones mutated shared state, and which timers or callbacks crossed those boundaries. From there, the split along transport, command dispatch, state, and peripheral control became fairly obvious.
Rather than inventing style guides from scratch, we had Claude summarize the implicit conventions it observed in the existing clean code, and then used those as the refactoring targets for the rest. Three principles emerged:
- One responsibility per class, one mutation site per field. If a field was being written in three places, we refactored so only one method could mutate it.
- Pass cancellation through every async boundary. No exceptions.
- Return snapshots, not references. Any public getter on shared mutable state returned a copy.
These rules sound obvious, but before Claude cataloged every violation across sixty files, we had no idea how widespread the pattern breaks actually were.
Part 2 — Fixing Bugs and Logging Blind Spots
The audit surfaced bugs ranging from the embarrassing to the genuinely dangerous. We will walk through two representative examples and then describe the logging work, which turned out to have the highest operational return.
The “task is always faulted” bug
A senior engineer on the team had written a background task launcher that was supposed to log a critical message if the task failed. It looked something like this:
task.ContinueWith(t =>
{
if (t.IsFaulted || t.IsCompleted)
{
_logger.LogCritical("Background task faulted! {ex}", t.Exception);
}
});
Claude flagged this immediately. ContinueWith only runs after the antecedent completes, which means t.IsCompleted is always true inside the callback. Every normal, successful completion was being logged as a critical failure with a null exception. Worse, the parent health-check loop was looking at IsFaulted || IsCompleted on the returned continuation task, which normalizes to completed regardless of the antecedent — so the health loop was restarting the task on every one-second tick. A silent restart storm had been running in production for months, masked by the “critical” log spam nobody read anymore.
The fix was small:
task.ContinueWith(t =>
{
if (t.IsFaulted)
{
_logger.LogCritical(t.Exception, "Background task faulted");
}
}, TaskContinuationOptions.OnlyOnFaulted);
return task; // return the original, not the continuation
★ Insight ─────────────────────────────────────
- The key was returning the original task rather than the continuation. The health-check loop needs to observe the real task’s fault status, not a continuation that always completes normally.
TaskContinuationOptions.OnlyOnFaultedis belt-and-suspenders: even if someone later changes the predicate, the continuation will only fire on the fault path.
─────────────────────────────────────────────────
The “unit mismatch” bug
Another entry from the audit:
// waitTime is in seconds
await Task.Delay(waitTime);
Task.Delay expects milliseconds. A value intended to wait thirty seconds was waiting thirty milliseconds. This bug had lived in startup code for over a year. Nobody noticed because the system mostly worked — but a handful of intermittent initialization failures finally got attributed to it once Claude surfaced the issue alongside the documentation comment that explicitly said the unit was seconds.
await Task.Delay(TimeSpan.FromSeconds(waitTime));
We took the lesson and asked Claude to scan every Task.Delay call site. It found two more with ambiguous units and converted all of them to TimeSpan-based calls as a policy.
The logging overhaul
Logging was the area with the highest return on effort. The pattern was painfully consistent: important operations had no logs, unimportant operations had too many, and nothing was correlated. An operator investigating a failed command in the middle of the night had no way to trace a single request from the user interface through the coordinator into the device and back.
BEFORE AFTER
───────────────── ────────────────────────────
[10:42:01] INFO Cmd received [10:42:01] INFO CorrelationId=a7f2...
[10:42:01] INFO Processing Cmd received
[10:42:03] WARN Something happened [10:42:01] INFO CorrelationId=a7f2...
[10:42:05] INFO Done Processing {CommandId} for {DeviceId}
[10:42:03] WARN CorrelationId=a7f2...
Which command? Which device? TransportError at step {Step}
No way to join the dots. [10:42:05] INFO CorrelationId=a7f2...
Completed {CommandId} in {ElapsedMs}ms
We asked Claude to produce a logging plan. The plan identified 38 gaps across seven categories: missing correlation IDs, unlogged services, SafeFireAndForget callbacks with no error handler, missing audit trails on user-facing operations, log level misuse, missing high-performance LoggerMessage source-generator usage, and minimal test coverage for logging behavior.
The most impactful change was introducing correlation IDs at the message boundary and threading them through the pipeline via Serilog.LogContext. A single command could now be followed from hub entry, through the command handler, into domain events, and back to the response — all tagged with the same identifier.
Just as important were the places where the system was failing silently. One startup path loaded the in-memory device cache using SafeFireAndForget(). If that task threw during initialization, the service would start “successfully” but every later gateway lookup would fail because the cache was empty. Another path fired safety-related operations without any durable audit trail. These were not style issues. They were production forensics failures.
A representative fix for silent fire-and-forget failures (obfuscated):
// Before — exception silently swallowed
initializationTask.SafeFireAndForget();
// After — critical startup failure is loud
initializationTask.SafeFireAndForget(ex =>
logger.LogCritical(ex,
"Initial data fetch failed — service started with empty cache"));
★ Insight ─────────────────────────────────────
- The
SafeFireAndForgethelper is popular in mobile and server .NET code because it lets you call async methods from sync contexts. But its default behavior — swallow everything — is a silent failure generator. Every high-value call site needed anonExceptionhandler, and some startup-path failures deservedLogCritical, notLogError. - The biggest logging win was not “more logs.” It was better logs: correlation, identifiers, and audit trails on operations that operators actually care about.
─────────────────────────────────────────────────
We added logging assertions around key paths and used them to catch regressions, but this was not a codebase with exhaustive log-level test coverage. The useful lesson was narrower: once logging becomes part of your operational contract, it deserves tests just like any other behavior.
Part 3 — Eliminating Race Conditions
This was the longest phase and the one with the most learning. Race conditions are the pathology that legacy .NET codebases are most prone to, because C# makes it very easy to share a Dictionary or a bool between threads without anything shouting at you.
One of the concurrency audits found 44 race conditions across a service and its related components. They fell into six archetypes:
ARCHETYPE COUNT
───────────────────────────────────────────── ─────
1. Non-thread-safe collection shared across 12
SignalR handlers, timers, and UI thread
2. Plain bool / enum flag read and written 9
from different threads (no volatile)
3. Timer callback racing with Dispose or 7
reassignment of the same timer field
4. async void in timer / event contexts 6
with no try-catch
5. Check-then-act on state that can change 6
across an await (TOCTOU)
6. Fire-and-forget background loops with 4
no cancellation or restart monitoring
Those categories appeared across the broader set of audits as well. We address the first three below.
Archetype 1 — Unprotected shared collection
Pattern we found, obfuscated:
public readonly Dictionary<DeviceId, DeviceState> DeviceCollection = new();
// Written from hub callback thread
DeviceCollection.Add(id, state);
// Enumerated from UI-bound property getter
public IEnumerable<DeviceState> AllDevices => DeviceCollection.Values;
// Cleared from state machine event
DeviceCollection.Clear();
Three threads, zero synchronization. The first time a user opened the device list while a state transition fired, we got an InvalidOperationException from the enumerator. In a test environment it was easy to reproduce; in production it took months.
The fix had two reasonable shapes. For dictionaries where we needed cheap concurrent access, ConcurrentDictionary<TKey, TValue> was often the right answer. For dictionaries where we wanted atomic “swap the whole thing” semantics — for example, replacing the entire device list at login — we used an ImmutableDictionary and a single-reference swap:
private ImmutableDictionary<DeviceId, DeviceState> _devices =
ImmutableDictionary<DeviceId, DeviceState>.Empty;
public ImmutableDictionary<DeviceId, DeviceState> Devices => _devices;
public void ReplaceAll(IEnumerable<KeyValuePair<DeviceId, DeviceState>> items)
{
_devices = items.ToImmutableDictionary();
}
public void AddOrUpdate(DeviceId id, DeviceState state)
{
ImmutableInterlocked.AddOrUpdate(ref _devices, id, state, (_, _) => state);
}
★ Insight ─────────────────────────────────────
ImmutableInterlocked.AddOrUpdategives you atomic single-writer-multiple-reader semantics without a lock. The reader gets a consistent snapshot because the dictionary reference they captured is literally immutable.- This was not a universal replacement for locks. In some audited code, a plain lock was simpler and safer because readers and writers also needed to coordinate side effects like event raises or timer replacement.
─────────────────────────────────────────────────
Archetype 2 — Plain flag across threads
The smallest possible bug with the largest possible impact:
private static bool _isBusy;
public static void BeginWork()
{
_isBusy = true;
Task.Run(() =>
{
while (_isBusy) // compiler may hoist this read out of the loop
{
DoStep();
}
});
}
public static void StopWork() => _isBusy = false;
The caller signals StopWork, the background task never sees the write, and the app hangs. The fix is either volatile or — better — a CancellationTokenSource:
private static CancellationTokenSource? _cts;
public static void BeginWork()
{
_cts = new CancellationTokenSource();
var token = _cts.Token;
Task.Run(() =>
{
while (!token.IsCancellationRequested)
{
DoStep();
}
}, token);
}
public static void StopWork()
{
_cts?.Cancel();
_cts?.Dispose();
_cts = null;
}
★ Insight ─────────────────────────────────────
- A
CancellationTokenhas the cross-thread memory semantics baked in — the reader always sees the cancelled state afterCancel()returns. You do not have to think aboutvolatilebecause you delegated that worry to the framework. - A secondary benefit:
CancellationTokencomposes. You can pass it toTask.Delay,HttpClient.SendAsync, database calls, and loop checks with a single mechanism. Avolatile boolcannot do that.
─────────────────────────────────────────────────
Archetype 3 — Timer callback racing its own field
This one was the most subtle. A service had a reusable timer field that was reassigned on restart:
_heartbeatTimer = new Timer(HeartbeatInterval);
_heartbeatTimer.Elapsed += OnHeartbeatElapsed;
_heartbeatTimer.AutoReset = false;
_heartbeatTimer.Start();
If the caller invoked this twice quickly, the first timer’s Elapsed handler could still fire after the field had been reassigned. The handler then mutated the “current” timer state even though it was the previous timer’s callback. Worse, the old timer was orphaned — it was still alive on the garbage collector’s finalizer queue, still capable of running its callback one more time.
The fix was to wrap the swap in a lock and eagerly stop-and-dispose the prior timer:
private readonly object _timerLock = new();
private Timer? _heartbeatTimer;
private void ReplaceHeartbeatTimer(TimeSpan interval)
{
lock (_timerLock)
{
if (_heartbeatTimer is not null)
{
_heartbeatTimer.Stop();
_heartbeatTimer.Elapsed -= OnHeartbeatElapsed;
_heartbeatTimer.Dispose();
}
_heartbeatTimer = new Timer(interval.TotalMilliseconds)
{
AutoReset = false,
};
_heartbeatTimer.Elapsed += OnHeartbeatElapsed;
_heartbeatTimer.Start();
}
}
We also audited every Timer.Elapsed handler we could find for async void lambdas. An exception thrown out of async void can tear down the process or vanish into an unobserved failure path depending on context. In either case, it is unacceptable in infrastructure code. The fix was to wrap the handler and surface the failure explicitly:
_disconnectTimer.Elapsed += async (_, _) =>
{
try
{
await PutOfflineAsync();
if (_publisher is not null)
{
await _publisher.PublishAllEventsAsync(this);
}
}
catch (Exception ex)
{
_onError?.Invoke(ex);
}
};
The _onError callback was injected at construction time, which kept the domain layer free of an ILogger dependency but still let failures be surfaced by the application layer. That single pattern — inject an Action<Exception> at the seam — let us rescue dozens of silent failure sites across both services.
The burndown
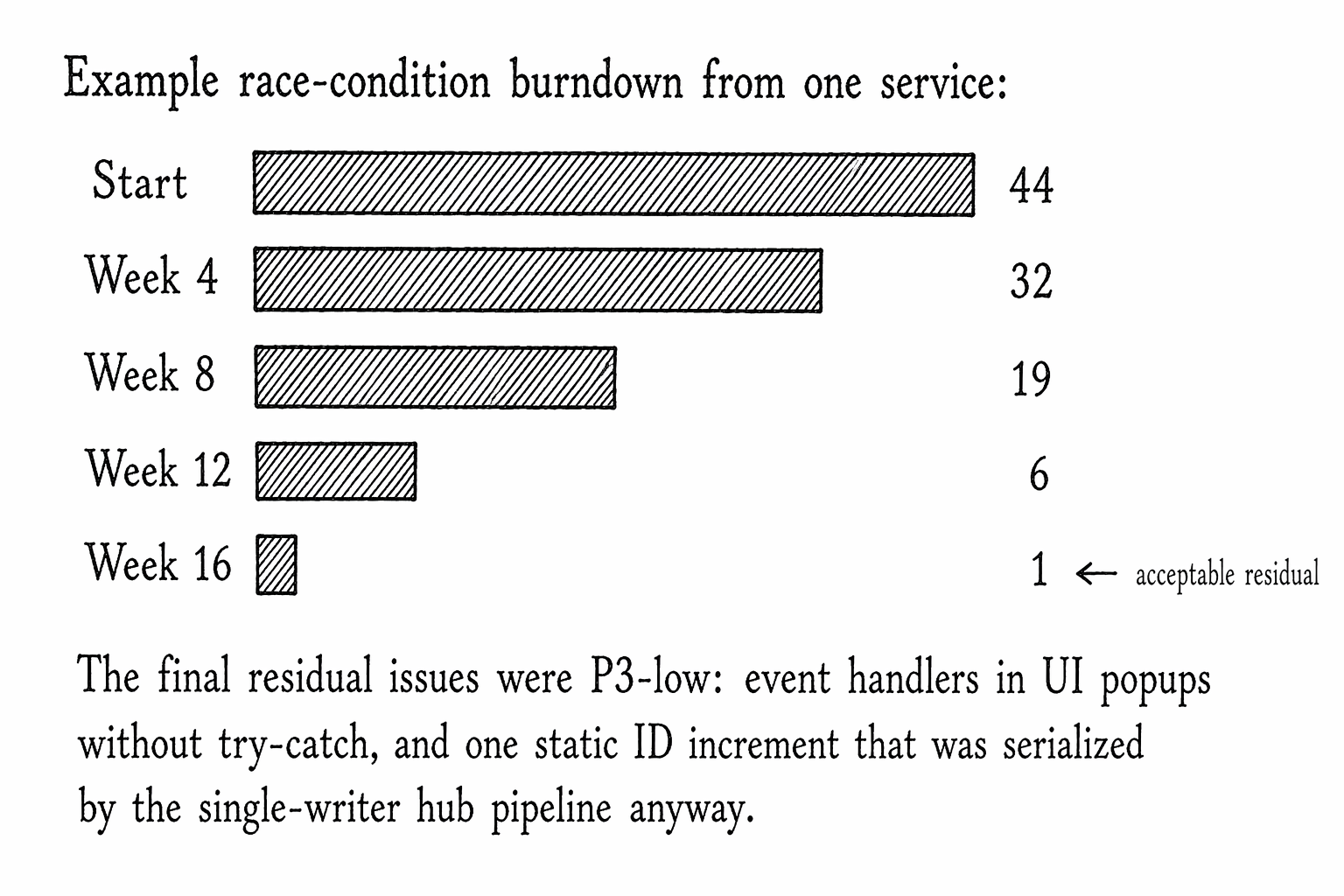
We did not fix all 44. We explicitly chose to leave one. It was a static integer increment in a path that was already serialized by the SignalR hub pipeline — meaning a race was theoretically possible but not reachable given how the method was called. We documented the reasoning and moved on. Not every bug is worth fixing, but every bug is worth understanding.
Part 4 — Reducing Technical Debt
“Technical debt” is a vague term, so we tried to reduce it to observable indicators. We tracked five, all derived from audit output:
Indicator Start Mid Later
───────────────────────────────── ────── ──── ────
Hardcoded secrets in source 3 0 0
Files commented out in entirety 4 1 0
TODO/FIXME comments 28 19 11
Handlers throwing NotImplemented 5 2 0
Services without ILogger injection 4 1 0
The secret audit was the single highest-leverage activity we did. Claude found a hardcoded GitHub personal access token in nuget.config — a file not covered by .gitignore. We rotated the token, moved it to a CI secret, and added the file to .gitignore within the same hour. An AES key was hardcoded in a crypto helper; we moved it to environment-variable-backed configuration and generated a random IV per encryption instead of the all-zeros IV that had shipped.
The remaining eleven TODO comments were all triaged. Each one either got a ticket, got a documentation comment explaining why we were leaving it, or was deleted because the thing it was pointing at no longer existed.
Testing Strategy Throughout
For the risky changes, the workflow was:
┌──────────────────────────────────────────────────────┐
│ 1. Write the failing test that captures the defect. │
│ 2. Ask Claude to propose the minimal fix. │
│ 3. Apply the fix, run the test, watch it go green. │
│ 4. Run the full suite to catch regressions. │
└──────────────────────────────────────────────────────┘
For race condition fixes this was not trivial. Concurrency bugs do not reliably reproduce. We leaned on two techniques:
- Deterministic stress harnesses. For collection-access issues, we wrote tests that spun up dozens of tasks all hammering the same API, then asserted invariants. Before the fix, these tests failed within ten iterations. After, they ran ten thousand iterations clean.
- Injectable time. For timer-related issues, we replaced
System.Timers.Timerwith a small abstraction that accepted a test clock, so the test could advance time manually and observe every callback fire in a known order.
A representative stress test (obfuscated):
[Fact]
public async Task Concurrent_AddOrUpdate_does_not_throw_or_lose_data()
{
var service = new DeviceRegistry();
const int WRITERS = 16;
const int ITERATIONS = 500;
var writers = Enumerable.Range(0, WRITERS).Select(w => Task.Run(() =>
{
for (int i = 0; i < ITERATIONS; i++)
{
var id = new DeviceId(w * ITERATIONS + i);
service.AddOrUpdate(id, new DeviceState(id, online: true));
}
})).ToArray();
var reader = Task.Run(() =>
{
int seen = 0;
while (seen < WRITERS * ITERATIONS)
{
seen = service.Devices.Count;
}
});
await Task.WhenAll(writers.Concat(new[] { reader }));
service.Devices.Should().HaveCount(WRITERS * ITERATIONS);
}
Before the fix, this test intermittently threw InvalidOperationException from the reader. After the synchronization change, it ran clean repeatedly.
Not every defect was amenable to strict test-first development. Some issues were better handled as:
- a small reproducer plus code review,
- a logging assertion on a failure path,
- or an integration test added after the fix when the seam became testable.
The practical lesson was not “TDD solves legacy systems.” It was narrower: if you are changing concurrency, startup, or observability logic, you need some repeatable proof that the system got safer.
What Worked, What Surprised Us
Three things worked far better than expected.
The audit was the unlock. The moment we had a single markdown document listing every issue by severity, with file and line references, the work became tractable. Without it we would have spent the whole project arguing about priorities.
Claude’s plans were often better than our gut priorities. The recommended fix order consistently put safety-critical issues ahead of ergonomics, even when a developer might have reached for the more satisfying refactor first. Following the plan rather than the vibe saved us from merging a “nice” change while a real bug was still live.
Small, tight edits compounded. The average fix was under twenty lines. The average PR was under two hundred. We deliberately resisted the temptation to bundle changes. Small PRs reviewed fast; fast review meant more PRs per week; more PRs per week meant the backlog actually burned down instead of drifting.
Two things surprised us.
Logging gave the best ROI of any category. We initially ranked logging as a medium-priority cleanup. In practice, the correlation-ID work and startup-failure visibility changed how fast we could debug real incidents.
The residual race conditions were the right call to leave alone. We originally planned to hit zero. Once the count dropped into the single digits, the remaining ones were all in paths that were serialized by upstream mechanisms or would only fire under contention we could not realistically reproduce. Fixing them would have churned a lot of code for no measurable benefit. “Document and move on” turned out to be a valid move.
A Playbook You Can Steal
If you are staring down a legacy codebase of your own, here is the compact version of the playbook:
- Ask Claude to audit a single module. Start narrow. Get the markdown output.
- Tag every issue with severity. Safety-critical first, data-integrity next, everything else by effort.
- Write the failing test before the fix. Every single time. No exceptions, even for one-line changes.
- Keep PRs small. One issue, one PR. Your reviewers will thank you and your burndown will be honest.
- Regenerate the audit monthly. New issues creep in. Catching them when they are one line old is cheap.
- Invest in logging early. Correlation IDs and structured log tests repay their cost within weeks.
- Delete more than you write. Commented-out files, stale TODOs, unused branches — none of them are getting better with age.
The core realization is that Claude is not a replacement for engineering judgment. It is a tireless pair for the parts of engineering that humans are worst at: the inventory, the tabular bookkeeping, the “did we check every Dictionary in the codebase?” grind. Pairing Claude’s completeness with a human’s priority-setting turns the dreaded “tech debt week” into something closer to a steady drumbeat of small, confident improvements.
If I were distilling this into one rule for engineering teams, it would be this: use Claude to widen the search space, not to waive review. Let it find the patterns, draft the boring fixes, and keep the backlog honest. But keep the decisions about severity, test depth, and merge readiness with engineers who understand the system’s actual failure modes.
And every time one of those improvements lands — every time a race condition that used to page the on-call engineer at three in the morning stops paging anyone — you feel the debt getting lighter. That is the whole point.
Written from the trenches of a real mission-critical .NET codebase. Names, domains, and code samples have been obfuscated; the patterns and lessons are exactly as we found them.